Building a Data Science Pipeline
I attended Wolfram’s “Building a Data Science Pipeline” webinar today, presented by Abrita Chakravarty.
Here’s the diagram of the pipeline presented. Pretty conventional.
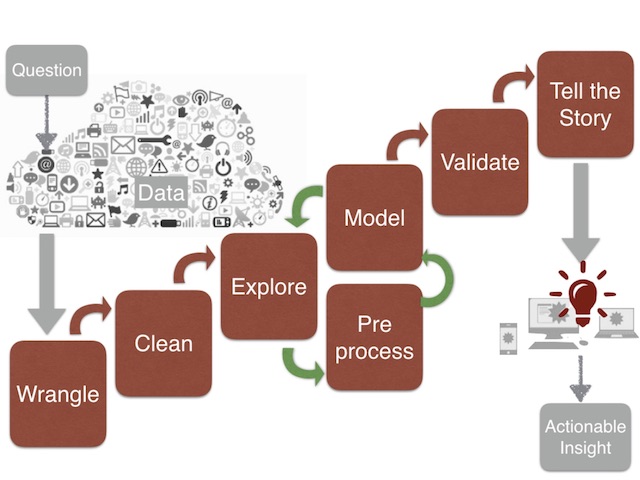
(Image copyright Wolfram Research)
The primary example used was a simple recipe classification project: classifying list of ingredients in the pantry by cuisine type to determine which recipes might work with what is on hand. (Yes, a little forced, I know.) Chakravarty walked through importing data (in JSON format), doing a little tidying up, partitioning the data into training and testing sets, running a few iterations of training, testing, and interpreting results.
It was a decent overview of supervised learning for classification, but their (implicit) pitch was not sufficiently compelling to induce a change of toolkits.
If you’re interested in seeing the workbooks they provided, please let me know.